With the growing success of neural networks, there is a corresponding need to be able to explain their decisions — including building confidence about how they will behave in the real-world, detecting model bias, and for scientific curiosity.
In order to do so, we need to both construct deep abstractions and reify (or instantiate) them in rich interfaces
The machine learning community has primarily focused on developing powerful methods, such as feature visualization
In this article, we treat existing interpretability methods as fundamental and composable building blocks for rich user interfaces. We find that these disparate techniques now come together in a unified grammar, fulfilling complementary roles in the resulting interfaces. Moreover, this grammar allows us to systematically explore the space of interpretability interfaces, enabling us to evaluate whether they meet particular goals. We will present interfaces that show what the network detects and explain how it develops its understanding, while keeping the amount of information human-scale. For example, we will see how a network looking at a labrador retriever detects floppy ears and how that influences its classification.
In this article, we use GoogLeNet
Making Sense of Hidden Layers
Much of the recent work on interpretability is concerned with a neural network’s input and output layers. Arguably, this focus is due to the clear meaning these layers have: in computer vision, the input layer represents values for the red, green, and blue color channels for every pixel in the input image, while the output layer consists of class labels and their associated probabilities.
However, the power of neural networks lies in their hidden layers — at every layer, the network discovers a new representation of the input. In computer vision, we use neural networks that run the same feature detectors at every position in the image. We can think of each layer’s learned representation as a three-dimensional cube. Each cell in the cube is an activation, or the amount a neuron fires. The x- and y-axes correspond to positions in the image, and the z-axis is the channel (or detector) being run.
To make a semantic dictionary, we pair every neuron activation with a visualization of that neuron and sort them by the magnitude of the activation. This marriage of activations and feature visualization changes our relationship with the underlying mathematical object. Activations now map to iconic representations, instead of abstract indices, with many appearing to be similar to salient human ideas, such as “floppy ear,” “dog snout,” or “fur.”
Semantic dictionaries are powerful not just because they move away from meaningless indices, but because they express a neural network’s learned abstractions with canonical examples. With image classification, the neural network learns a set of visual abstractions and thus images are the most natural symbols to represent them. Were we working with audio, the more natural symbols would most likely be audio clips. This is important because when neurons appear to correspond to human ideas, it is tempting to reduce them to words. Doing so, however, is a lossy operation — even for familiar abstractions, the network may have learned a deeper nuance. For instance, GoogLeNet has multiple floppy ear detectors that appear to detect slightly different levels of droopiness, length, and surrounding context to the ears. There also may exist abstractions which are visually familiar, yet that we lack good natural language descriptions for: for example, take the particular column of shimmering light where sun hits rippling water. Moreover, the network may learn new abstractions that appear alien to us — here, natural language would fail us entirely! In general, canonical examples are a more natural way to represent the foreign abstractions that neural networks learn than native human language.
By bringing meaning to hidden layers, semantic dictionaries set the stage for our existing interpretability techniques to be composable building blocks. As we shall see, just like their underlying vectors, we can apply dimensionality reduction to them. In other cases, semantic dictionaries allow us to push these techniques further. For example, besides the one-way attribution that we currently perform with the input and output layers, semantic dictionaries allow us to attribute to-and-from specific hidden layers. In principle, this work could have been done without semantic dictionaries but it would have been unclear what the results meant.
What Does the Network See?
Applying this technique to all the activation vectors allows us to not only see what the network detects at each position, but also what the network understands of the input image as a whole.
And, by working across layers (eg. “mixed3a”, “mixed4d”), we can observe how the network’s understanding evolves: from detecting edges in earlier layers, to more sophisticated shapes and object parts in the latter.
These visualizations, however, omit a crucial piece of information: the magnitude of the activations. By scaling the area of each cell by the magnitude of the activation vector, we can indicate how strongly the network detected features at that position:
How Are Concepts Assembled?
Feature visualization helps us answer what the network detects, but it does not answer how the network assembles these individual pieces to arrive at later decisions, or why these decisions were made.
Attribution is a set of techniques that answers such questions by explaining the relationships between neurons.
There are a wide variety of approaches to attribution
For spatial attribution, we do an additional trick. GoogLeNet’s strided max pooling introduces a lot of noise and checkerboard patterns to it’s gradients
The notebooks attached to diagrams provide reference implementations.
Spatial Attribution with Saliency Maps
The most common interface for attribution is called a saliency map — a simple heatmap that highlights pixels of the input image that most caused the output classification. We see two weaknesses with this current approach.
First, it is not clear that individual pixels should be the primary unit of attribution. The meaning of each pixel is extremely entangled with other pixels, is not robust to simple visual transforms (e.g., brightness, contrast, etc.), and is far-removed from high-level concepts like the output class. Second, traditional saliency maps are a very limited type of interface — they only display the attribution for a single class at a time, and do not allow you to probe into individual points more deeply. As they do not explicitly deal with hidden layers, it has been difficult to fully explore their design space.
We instead treat attribution as another user interface building block, and apply it to the hidden layers of a neural network.
In doing so, we change the questions we can pose.
Rather than asking whether the color of a particular pixel was important for the “labrador retriever” classification, we instead ask whether the high-level idea detected at that position (such as “floppy ear”) was important.
This approach is similar to what Class Activation Mapping (CAM) methods
The above interface affords us a more flexible relationship with attribution.
To start, we perform attribution from each spatial position of each hidden layer shown to all 1,000 output classes.
In order to visualize this thousand-dimensional vector, we use dimensionality reduction to produce a multi-directional saliency map.
Overlaying these saliency maps on our magnitude-sized activation grids provides an information scent
Perhaps most interestingly, this interface allows us to interactively perform attribution between hidden layers. On hover, additional saliency maps mask the hidden layers, in a sense shining a light into their black boxes. This type of layer-to-layer attribution is a prime example of how carefully considering interface design drives the generalization of our existing abstractions for interpretability.
With this diagram, we have begun to think of attribution in terms of higher-level concepts. However, at a particular position, many concepts are being detected together and this interface makes it difficult to split them apart. By continuing to focus on spatial positions, these concepts remain entangled.
Channel Attribution
Saliency maps implicitly slice our cube of activations by applying attribution to the spatial positions of a hidden layer. This aggregates over all channels and, as a result, we cannot tell which specific detectors at each position most contributed to the final output classification.
An alternate way to slice the cube is by channels instead of spatial locations.
Doing so allows us to perform channel attribution: how much did each detector contribute to the final output?
(This approach is similar to contemporaneous work by Kim et al.
This diagram is analogous to the previous one we saw: we conduct layer-to-layer attribution but this time over channels rather than spatial positions. Once again, we use the icons from our semantic dictionary to represent the channels that most contribute to the final output classification. Hovering over an individual channel displays a heatmap of its activations overlaid on the input image. The legend also updates to show its attribution to the output classes (i.e., what are the top classes this channel supports?). Clicking a channel allows us to drill into the layer-to-layer attributions, identifying the channels at lower layers that most contributed as well as the channels at higher layers that are most supported.
While these diagrams focus on layer-to-layer attribution, it can still be valuable to focus on a single hidden layer. For example, the teaser figure allows us to evaluate hypotheses for why one class succeeded over the other.
Attribution to spatial locations and channels can reveal powerful things about a model, especially when we combine them together. Unfortunately, this family of approaches is burdened by two significant problems. On the one hand, it is very easy to end up with an overwhelming amount of information: it would take hours of human auditing to understand the long-tail of channels that slightly impact the output. On the other hand, both the aggregations we have explored are extremely lossy and can miss important parts of the story. And, while we could avoid lossy aggregation by working with individual neurons, and not aggregating at all, this explodes the first problem combinatorially.
Making Things Human-Scale
In previous sections, we’ve considered three ways of slicing the cube of activations: into spatial activations, channels, and individual neurons. Each of these has major downsides. If one only uses spatial activations or channels, they miss out on very important parts of the story. For example it’s interesting that the floppy ear detector helped us classify an image as a Labrador retriever, but it’s much more interesting when that’s combined with the locations that fired to do so. One can try to drill down to the level of neurons to tell the whole story, but the tens of thousands of neurons are simply too much information. Even the hundreds of channels, before being split into individual neurons, can be overwhelming to show users!
If we want to make useful interfaces into neural networks, it isn’t enough to make things meaningful. We need to make them human scale, rather than overwhelming dumps of information. The key to doing so is finding more meaningful ways of breaking up our activations. There is good reason to believe that such decompositions exist. Often, many channels or spatial positions will work together in a highly correlated way and are most useful to think of as one unit. Other channels or positions will have very little activity, and can be ignored for a high-level overview. So, it seems like we ought to be able to find better decompositions if we had the right tools.
There is an entire field of research, called matrix factorization, that studies optimal strategies for breaking up matrices. By flattening our cube into a matrix of spatial locations and channels, we can apply these techniques to get more meaningful groups of neurons. These groups will not align as naturally with the cube as the groupings we previously looked at. Instead, they will be combinations of spatial locations and channels. Moreover, these groups are constructed to explain the behavior of a network on a particular image. It would not be effective to reuse the same groupings on another image; each image requires calculating a unique set of groups.
The groups that come out of this factorization will be the atoms of the interface a user works with. Unfortunately, any grouping is inherently a tradeoff between reducing things to human scale and, because any aggregation is lossy, preserving information. Matrix factorization lets us pick what our groupings are optimized for, giving us a better tradeoff than the natural groupings we saw earlier.
The goals of our user interface should influence what we optimize our matrix factorization to prioritize. For example, if we want to prioritize what the network detected, we would want the factorization to fully describe the activations. If we instead wanted to prioritize what would change the network’s behavior, we would want the factorization to fully describe the gradient. Finally, if we want to prioritize what caused the present behavior, we would want the factorization to fully describe the attributions. Of course, we can strike a balance between these three objectives rather than optimizing one to the exclusion of the others.
In the following diagram, we’ve constructed groups that prioritize the activations, by factorizing the activations
This figure only focuses at a single layer but, as we saw earlier, it can be useful to look across multiple layers to understand how a neural network assembles together lower-level detectors into higher-level concepts.
The groups we constructed before were optimized to understand a single layer independent of the others. To understand multiple layers together, we would like each layer’s factorization to be “compatible” — to have the groups of earlier layers naturally compose into the groups of later layers. This is also something we can optimize the factorization for
Consider the attribution from every neuron in the layer to the set of N groups we want it to be compatible with.
The basic idea is to split each entry in the activation matrix into N entries on the channel dimension, spreading the values proportional to the absolute value of its attribution to the corresponding group.
Any factorization of this matrix induces a factorization of the original matrix by collapsing the duplicated entries in the column factors.
However, the resulting factorization tries to create separate factors when the activation of the same channel has different attributions in different places.
In this section, we recognize that the way in which we break apart the cube of activations is an important interface decision. Rather than resigning ourselves to the natural slices of the cube of activations, we construct more optimal groupings of neurons. These improved groupings are both more meaningful and more human-scale, making it less tedious for users to understand the behavior of the network.
Our visualizations have only begun to explore the potential of alternate bases in providing better atoms for understanding neural networks.
For example, while we focus on creating smaller numbers of directions to explain individual examples, there’s recently been exciting work finding “globally” meaningful directions
The Space of Interpretability Interfaces
The interface ideas presented in this article combine building blocks such as feature visualization and attribution. Composing these pieces is not an arbitrary process, but rather follows a structure based on the goals of the interface. For example, should the interface emphasize what the network recognizes, prioritize how its understanding develops, or focus on making things human-scale. To evaluate such goals, and understand the tradeoffs, we need to be able to systematically consider possible alternatives.
We can think of an interface as a union of individual elements.
Each element displays a specific type of content (e.g., activations or attribution) using a particular style of presentation (e.g., feature visualization or traditional information visualization). This content lives on substrates defined by how given layers of the network are broken apart into atoms, and may be transformed by a series of operations (e.g., to filter it or project it onto another substrate). For example, our semantic dictionaries use feature visualization to display the activations of a hidden layer's neurons.
One way to represent this way of thinking is with a formal grammar, but we find it helpful to think about the space visually. We can represent the network’s substrate (which layers we display, and how we break them apart) as a grid, with the content and style of presentation plotted on this grid as points and connections.
This setup gives us a framework to begin exploring the space of interpretability interfaces step by step. For instance, let us consider our teaser figure again. Its goal is to help us compare two potential classifications for an input image.


To understand a classification, we focus on the channels of the
mixed4d layer. Feature visualization makes these channels meaningful.

Next, we filter for specific classes by calculating the output attribution.
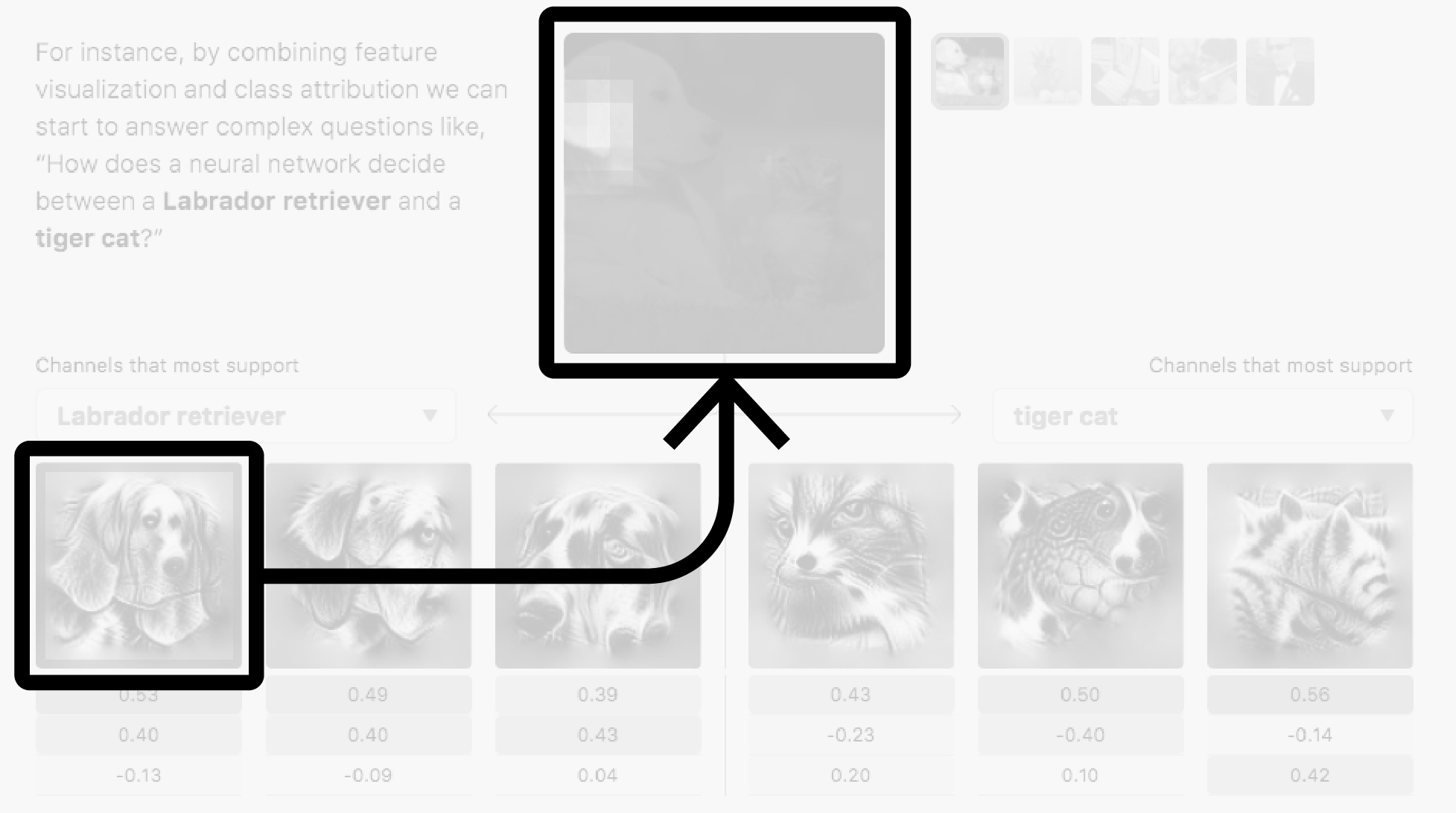
Hovering over channels, we get a heatmap of spatial activations.
In this article, we have only scratched the surface of possibilities. There are lots of combinations of our building blocks left to explore, and the design space gives us a way to do so systematically.
Moreover, each building block represents a broad class of techniques. Our interfaces take only one approach but, as we saw in each section, there are a number of alternatives for feature visualization, attribution, and matrix factorization. An immediate next step would be to try using these alternate techniques, and research ways to improve them.
Finally, this is not the complete set of building blocks; as new ones are discovered, they expand the space.
For example, Koh & Liang. suggest ways of understanding the influence of dataset examples on model behavior

Beyond interfaces for analyzing model behavior, if we add model parameters as a substrate, the design space now allows us to consider interfaces for taking action on neural networks.
Another exciting possibility is interfaces for comparing multiple models.
For instance, we might want to see how a model evolves during training, or how it changes when you transfer it to a new task.
Or, we might want to understand how a whole family of models compares to each other.
Existing work has primarily focused on comparing the output behavior of models
How Trustworthy Are These Interfaces?
In order for interpretability interfaces to be effective, we must trust the story they are telling us. We perceive two concerns with the set of building blocks we currently use. First, do neurons have a relatively consistent meaning across different input images, and is that meaning accurately reified by feature visualization? Semantic dictionaries, and the interfaces that build on top of them, are premised off this question being true. Second, does attribution make sense and do we trust any of the attribution methods we presently have?
Much prior research has found that directions in neural networks are semantically meaningful
For more details, see
the article’s appendix and the guided tour in
@ch402′s Twitter thread. We’re actively investigating why GoogLeNet’s neurons seem more meaningful.
With regards to attribution, recent work suggests that many of our current techniques are unreliable
Model behavior is extremely complex, and our current building blocks force us to show only specific aspects of it.
An important direction for future interpretability research will be developing techniques that achieve broader coverage of model behavior.
But, even with such improvements, we anticipate that a key marker of trustworthiness will be interfaces that do not mislead.
Interacting with the explicit information displayed should not cause users to implicitly draw incorrect assessments about the model (we see a similar principle articulated by Mackinlay for data visualization
Trusting our interfaces is essential for many of the ways we want to use interpretability. This is both because the stakes can be high (as in safety and fairness) and also because ideas like training models with interpretability feedback put our interpretability techniques in the middle of an adversarial setting.
Conclusion & Future Work
There is a rich design space for interacting with enumerative algorithms, and we believe an equally rich space exists for interacting with neural networks. We have a lot of work left ahead of us to build powerful and trustworthy interfaces for interpretability. But, if we succeed, interpretability promises to be a powerful tool in enabling meaningful human oversight and in building fair, safe, and aligned AI systems.