Neural networks trained to classify images have a remarkable — and surprising! — capacity to generate images.
Techniques such as DeepDream
All these techniques work in roughly the same way. Neural networks used in computer vision have a rich internal representation of the images they look at. We can use this representation to describe the properties we want an image to have (e.g. style), and then optimize the input image to have those properties. This kind of optimization is possible because the networks are differentiable with respect to their inputs: we can slightly tweak the image to better fit the desired properties, and then iteratively apply such tweaks in gradient descent.
Typically, we parameterize the input image as the RGB values of each pixel, but that isn’t the only way. As long as the mapping from parameters to images is differentiable, we can still optimize alternative parameterizations with gradient descent.
1: As long as an image parameterization is differentiable, we can backpropagate ( ) through it.
Differentiable image parameterizations invite us to ask “what kind of image generation process can we backpropagate through?”
The answer is quite a lot, and some of the more exotic possibilities can create a wide range of interesting effects, including 3D neural art, images with transparency, and aligned interpolation.
Previous work using specific unusual image parameterizations
Why Does Parameterization Matter?
It may seem surprising that changing the parameterization of an optimization problem can significantly change the result, despite the objective function that is actually being optimized remaining the same. We see four reasons why the choice of parameterization can have a significant effect:
(1) - Improved Optimization -
Transforming the input to make an optimization problem easier — a technique called “preconditioning” — is a staple of optimization.
(2) - Basins of Attraction -
When we optimize the input to a neural network, there are often many different solutions, corresponding to different local minima.
(3) - Additional Constraints - Some parameterizations cover only a subset of possible inputs, rather than the entire space. An optimizer working in such a parameterization will still find solutions that minimize or maximize the objective function, but they’ll be subject to the constraints of the parameterization. By picking the right set of constraints, one can impose a variety of constraints, ranging from simple constraints (e.g., the boundary of the image must be black), to rich, subtle constraints.
(4) - Implicitly Optimizing other Objects - A parameterization may internally use a different kind of object than the one it outputs and we optimize for. For example, while the natural input to a vision network is an RGB image, we can parameterize that image as a rendering of a 3D object and, by backpropagating through the rendering process, optimize that instead. Because the 3D object has more degrees of freedom than the image, we generally use a stochastic parameterization that produces images rendered from different perspectives.
In the rest of the article we give concrete examples where such approaches are beneficial and lead to surprising and interesting visual results.
Aligned Feature Visualization Interpolation
Feature visualization is most often used to visualize individual neurons,
but it can also be used to visualize combinations of neurons, in order to study how they interact
When we want to really understand the interaction between two neurons, we can go a step further and create multiple visualizations, gradually shifting the objective from optimizing one neuron to putting more weight on the other neuron firing. This is in some ways similar to interpolation in the latent spaces of generative models like GANs.
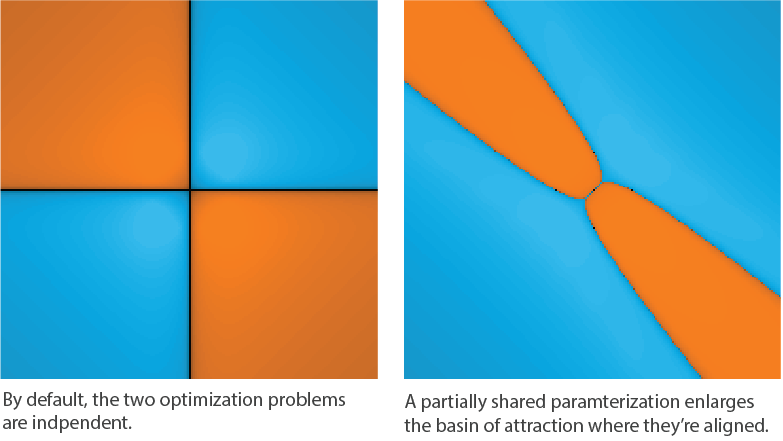
Despite this, there is a small challenge: feature visualization is stochastic. Even if you optimize for the exact same objective, the visualization will be laid out differently each time. Normally, this isn’t a problem, but it does detract from the interpolation visualizations. If we make them naively, the resulting visualizations will be unaligned: visual landmarks such as eyes appear in different locations in each image. This lack of alignment can make it harder to see the difference due to slightly different objectives, because they’re swamped by the much larger differences in layout.
We can see the issue with independent optimization if we look at the interpolated frames as an animation:
How can we achieve this aligned interpolation, where visual landmarks do not move between frames?
There are a number of possible approaches one could try
By partially sharing a parameterization between frames, we encourage the resulting visualizations to naturally align.
Intuitively, the shared parameterization provides a common reference for the displacement of visual landmarks, while the unique one gives to each frame its own visual appeal based on its interpolation weights.
This is an initial example of how differentiable parameterizations in general can be a useful additional tool in visualizing neural networks.
Style Transfer with non-VGG architectures
Neural style transfer has a mystery:
despite its remarkable success, almost all style transfer is done with variants of the VGG architecture
Several hypotheses have been proposed to explain why VGG works so much better than other models.
One suggested explanation is that VGG’s large size causes it to capture information that other models discard.
This extra information, the hypothesis goes, isn’t helpful for classification, but it does cause the model to work better for style transfer.
An alternate hypothesis is that other models downsample more aggressively than VGG, losing spatial information.
We suspect that there may be another factor: most modern vision models have checkerboard artifacts in their gradient
In previous work we found that a decorrelated parameterization can significantly improve optimization
4: Move the slider under “final image optimization” to compare optimization in pixel space with optimization in a decorrelated space. Both images were created with the same objective and differ only in their parameterization.
Let’s consider this change in a bit more detail. Style transfer involves three images: a content image, a style image, and the image we optimize.
All three of these feed into the CNN, and the style transfer objective
Our exact implementation can be found in the accompanying notebook. Note that it also uses transformation robustness
Compositional Pattern Producing Networks
So far, we’ve explored image parameterizations that are relatively close to how we normally think of images, using pixels or Fourier components.
In this section, we explore the possibility of (3) adding additional constraints to the optimization process by using a different parameterization.
More specifically, we parameterize our image as a neural network
CPPNs are neural networks that map positions to image colors:
By applying the CPPN to a grid of positions, one can make arbitrary resolution images. The parameters of the CPPN network — the weights and biases — determine what image is produced. Depending on the architecture chosen for the CPPN, pixels in the resulting image are constraint to share, up to a certain degree, the color of their neighbors.
Random parameters can produce aesthetically interesting images
Using CPPNs as image parameterization can add an interesting artistic quality to neural art, vaguely reminiscent of light-paintings.
Note that light-painting metaphor here is rather fragile: for example light composition is an additive process, while CPPNs can have negative-weighted connections between layers.
The visual quality of the generated images is heavily influenced by the architecture of the chosen CPPN. Not only the shape of the network, i.e., the number of layers and filters, plays a role, but also the chosen activation functions and normalization. For example, deeper networks produce more fine grained details compared to shallow ones. We encourage readers to experiment in generating different images by changing the architecture of the CPPN. This can be easily done by changing the code in the supplementary notebook.
The evolution of the patterns generated by the CPPN are artistic artifacts themselves. To maintain the metaphor of light-paintings, the optimization process correspond to an iterative adjustments of the beam directions and shapes. Because the iterative changes have a more global effect compared to, for example, a pixel parameterization, at the beginning of the optimization only major patterns are visible. By iteratively adjusting the weights, our imaginary beams are positioned in such a way that fine details emerge.

8:
Output of CPPNs during training. Control each video by hovering, or tapping it if you are on a mobile device.
By playing with this metaphor, we can also create a new kind of animation that morph one of the above images into a different one. Intuitively, we start from one of the light-paintings and we move the beams to create a different one. This result is in fact achieved by interpolating the weights of the CPPN representations of the two patterns. A number of intermediate frames are then generated by generating an image given the interpolated CPPN representation. As before, changes in the parameter have a global effect and create visually appealing intermediate frames.
9:
Interpolating CPPN weights between two learned points.
In this section we presented a parameterization that goes beyond a standard image representation. Neural networks, a CPPN in this case, can be used to parameterize an image that is optimized for a given objective function. More specifically, we combined a feature-visualization objective function with a CPPN parameterization to create infinite-resolution images of distinctive visual style.
Generation of Semi-Transparent Patterns
The neural networks used in this article were trained to receive 2D RGB images as input. Is it possible to use the same network to synthesize artifacts that span (4) beyond this domain? It turns out that we can do so by making our differentiable parameterization define a family of images instead of a single image, and then sampling one or a few images from that family at each optimization step. This is important because many of the objects we’ll explore optimizing have more degrees of freedom than the images going into the network.
To be concrete, let’s consider the case of semi-transparent images. These images have, in addition to the RGB channels, an alpha channel that encodes each pixel’s opacity (in the range ). In order to feed such images into a neural network trained on RGB images, we need to somehow collapse the alpha channel. One way to achieve this is to overlay the RGBA image on top of a background image using the standard alpha blending formula
,
where is the alpha channel of the image .
If we used a static background , such as black, the transparency would merely indicate pixel positions in which that background contributes directly to the optimization objective.
In fact, this is equivalent to optimizing an RGB image and making it transparent in areas where its color matches with the background!
Intuitively, we’d like transparent areas to correspond to something like “the content of this area could be anything.”
Building on this intuition, we use a different random background at every optimization step.
By default, optimizing our semi-transparent image will make the image fully opaque, so the network can always get its optimal input. To avoid this, we need to change our objective with an objective that encourages some transparency. We find it effective to replace the original objective with:
,
This new objective automatically balances the original objective with reducing the mean transparency. If the image becomes very transparent, it will focus on the original objective. If it becomes too opaque, it will temporarily stop caring about the original objective and focus on decreasing the average opacity.
11: Examples of the optimization of semi transparent images for different layers and units.
It turns out that the generation of semi-transparent images is useful in feature visualization.
Feature visualization aims to understand what neurons in a vision model are looking for, by creating images that maximally activate them.
Unfortunately, there is no way for these visualizations to distinguish which areas of an image strongly influence a neuron’s activation and those which only marginally do so.
Ideally, we would like a way for our visualizations to make this distinction in importance — one natural way to represent that a part of the image doesn’t matter is for it to be transparent. Thus, if we optimize an image with an alpha channel and encourage the overall image to be transparent, parts of the image that are unimportant according to the feature visualization objective should become transparent.
Efficient Texture Optimization through 3D Rendering
In the previous section, we were able to use a neural network for RGB images to create a semi-transparent RGBA image.
Can we push this even further, creating (4) other kinds of objects even further removed from the RGB input?
In this section we explore optimizing 3D objects for a feature-visualization objective
Our technique is similar to the approach that Athalye et al.
Before we can describe our approach, we first need to understand how a 3D object is stored and rendered on screen. The object’s geometry is usually saved as a collection of interconnected triangles called triangle mesh or, simply, mesh. To render a realistic model, a texture is painted over the mesh. The texture is saved as an image that is applied to the model by using the so called UV-mapping. Every vertex in the mesh is associated to a coordinate in the texture image. The model is then rendered, i.e. drawn on screen, by coloring every triangle with the region of the image that is delimited by the coordinates of its vertices.
A simple naive way to create the 3D object texture would be to optimize an image the normal way and then use it as a texture to paint on the object. However, this approach generates a texture that does not consider the underlying UV-mapping and, therefore, will create a variety of visual artifacts in the rendered object. First, seams are visible on the rendered texture, because the optimization is not aware of the underlying UV-mapping and, therefore, does not optimize the texture consistently along the split patches of the texture. Second, the generated patterns are randomly oriented on different parts of the object (see, e.g., the vertical and wiggly patterns) because they are not consistently oriented in the underlying UV-mapping. Finally generated patterns are inconsistently scaled because the UV-mapping does not enforce a consistent scale between triangle areas and their mapped triangle in the texture.
13:
3D model of the famous Stanford Bunny
We take a different approach. Instead of directly optimizing the texture, we optimize the texture through renderings of the 3D object, like those the user would eventually see. The following diagram presents an overview of the proposed pipeline:
We start the process by randomly initializing the texture with a Fourier parameterization. At every training iteration we sample a random camera position, which is oriented towards the center of the bounding box of the object, and we render the textured object as an image. We then backpropagate the gradient of the desired objective function, i.e., the feature of interest in the neural network, to the rendered image.
However, an update of the rendered image does not correspond to an update to the texture that we aim at optimizing. Hence, we need to further propagate the changes to the object’s texture. The propagation is easily implemented by applying a reverse UV-mapping, as for each pixel on screen we know its coordinate in the texture. By modifying the texture, during the following optimization iterations, the rendered image will incorporate the changes applied in the previous iterations.
15: Textures are generated by optimizing for a feature visualization objective function. Seams in the textures are hardly visible and the patterns are correctly oriented.
The resulting textures are consistently optimized along the cuts, hence removing the seams and enforcing an uniform orientation for the rendered object. Morever, since the function optimization is disentangled by the geometry of the object, the resolution of the texture can be arbitrary high. In the next section we will se how this framework can be reused for performing an artistic style transfer to the object’s texture.
Style Transfer for Textures through 3D Rendering
Now that we have established a framework for efficient backpropagation into the UV-mapped texture, we can use it to adapt existing style transfer techniques for 3D objects. Similarly to the 2D case, we aim at redrawing the original object’s texture with the style of a user-provided image. The following diagram presents an overview of the approach:
The algorithm works in similar way to the one presented in the previous section, starting from a randomly initialized texture. At each iteration, we sample a random view point oriented toward the center of the bounding box of the object and we render two images of it: one with the original texture, the content image, and one with the texture that we are currently optimizing, the learned image.
After the content image and learned image are rendered, we optimize for the style-transfer objective function introduced by Gatys et al.
17: Style Transfer onto various 3D models. Note that visual landmarks in the content texture, such as eyes, show up correctly in the generated texture.
Because every view is optimized independently, the optimization is forced to try to add all the style’s elements at every iteration.
For example, if we use as style image the Van Gogh’s “Starry Night” painting, stars will be added in every single view.
We found we obtain more pleasing results, such as those presented above, by introducing a sort of “memory” of the style of
previous views. To this end, we maintain moving averages of style-representing Gram matrices
over the recently sampled viewpoints. On each optimization iteration we compute the style loss against those averaged matrices,
instead of the ones computed for that particular view.
tf.stop_gradient method to substitute current Gram matrices
with their moving averages on forward pass, while still propagating the correct gradients
to the current Gram matrices.
An alternative approach, such as the one employed by
The resulting textures combine elements of the desired style, while preserving the characteristics of the original texture. Take as an example the model created by imposing Van Gogh’s starry night as style image. The resulting texture contains the rythmic and vigorous brush strokes that characterize Van Gogh’s work. However, despite the style image’s primarily cold tones, the resulting fur has a warm orange undertone as it is preserved from the original texture. Even more interesting is how the eyes of the bunny are preserved when different styles are transfered. For example, when the style is obtained from the Van Gogh’s painting, the eyes are transformed in a star-like swirl, while if Kandinsky’s work is used, they become abstract patterns that still resemble the original eyes.

Textured models produced with the presented method can be easily used with popular 3D modeling software or game engines. To show this, we 3D printed one of the designs as a real-world physical artifact
Conclusions
For the creative artist or researcher, there’s a large space of ways to parameterize images for optimization.
This opens up not only dramatically different image results, but also animations and 3D objects!
We think the possibilities explored in this article only scratch the surface.
For example, one could explore extending the optimization of 3D object textures to optimizing the material or reflectance — or even go the direction of Kato et al.
This article focused on differentiable image parameterizations, because they are easy to optimize and cover a wide range of possible applications.
But it’s certainly possible to optimize image parameterizations that aren’t differentiable, or are only partly differentiable, using reinforcement learning or evolutionary strategies